Recent AI-based 3D content creation has largely evolved along two paths: feed-forward image-to-3D
reconstruction approaches and 3D generative models trained with 2D or 3D supervision. In this work, we
show that existing feed-forward reconstruction methods can serve as effective latent encoders for training
3D generative models, thereby bridging these two paradigms. By reusing powerful pre-trained reconstruction
models, we avoid computationally expensive encoder network training and obtain rich 3D latent features for
generative modeling for free. However, the latent spaces of reconstruction models are not well-suited for
generative modeling due to their unstructured nature. To enable flow-based model training on these latent
features, we develop post-processing pipelines, including protocols to standardize the features and
spatial weighting to concentrate on important regions. We further incorporate a 2D image space perceptual
rendering loss to handle the high-dimensional latent spaces. Finally, we propose a multi-stream
transformer-based rectified flow architecture to achieve linear scaling and high-quality text-conditioned
3D generation. Our framework leverages the advancements of feed-forward reconstruction models to enhance
the scalability of 3D generative modeling, achieving both high computational efficiency and
state-of-the-art performance in text-to-3D generation.
Figure 1. Text-to-3D generation. Our TriFlow model is trained on triplanes from a pretrained feed-forward reconstruction model and can generate a high-quality 3D model in a few seconds. Left column: samples of a model trained on Objaverse LVIS. Right: samples of models fine-tuned on ShapeNet chairs and cars.
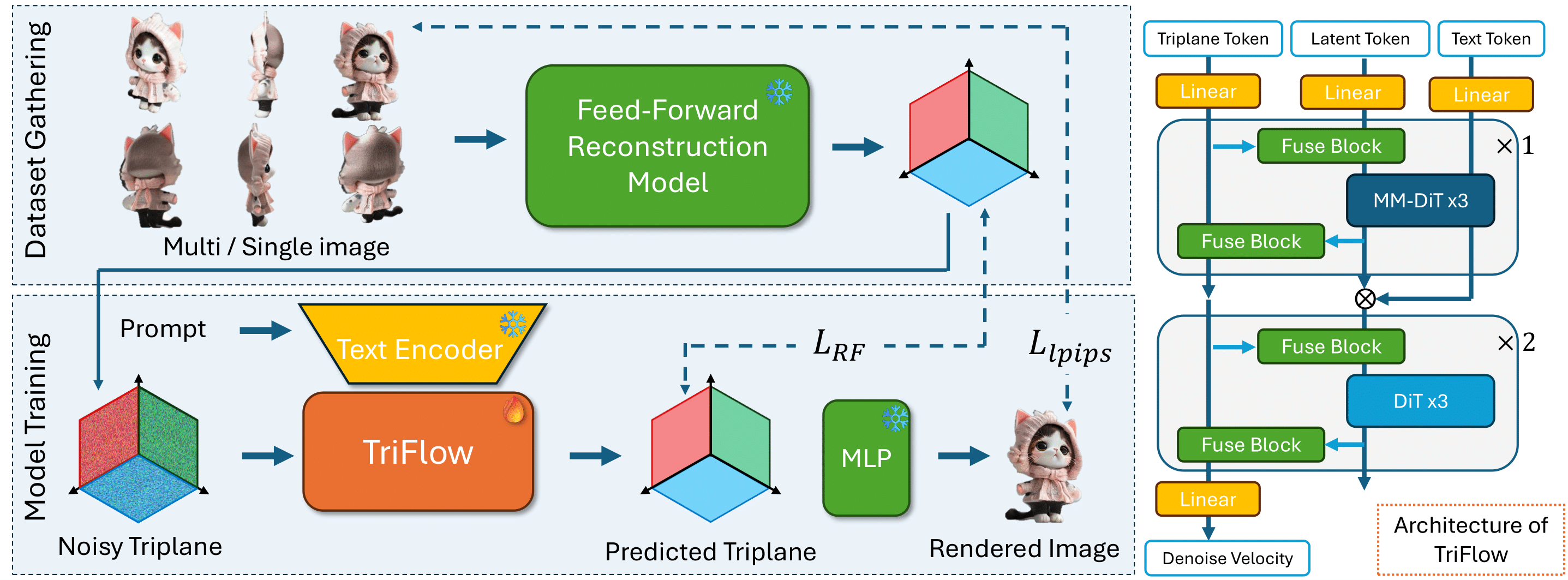
Figure 2. Overview of our image-to-3D generation pipeline and architecture. Our framework includes two main components: (1) a dataset preparation stage, where single-view or multi-view images are processed through a feed-forward image-to-triplane model to generate triplanes, and (2) TriFlow, a text-conditioned generative model trained on these triplanes using rectified-flow-based loss (LRF ) and perceptual loss (Llpips ) compared against the original images. On the right, we show our model architecture, a multi-stream transformer incorporating a combination of MM-DiT and DiT blocks. Note that ⊗ denotes concatenation between token streams.
Text-to-3D ShapNet Chair
blue living room chair
fancy dining room chair with sculpted wooden legs
green coffee table chair
metal bar chair
red office chair with wheels
white folding chair
wooden park bench
Text-to-3D ShapNet Car
blue race car
green suv car
long black luxury limousine
purple car with modern design
red Ferrari car
white police car
yellow school bus
Text-to-3D Objaverse
ancient clay pot
big green Christmas tree.
blue ceramic bowl.
blue jewelry necklace.
classic red fire hydrant.
classic wooden guitar.
computer monitor with flat screen.
fresh green apple.
glass jar.
golden yellow toilet.
jacket with modern design.
large pumpkin.
long computer keyboard.
metal lampost with a lantern on the top.
my little pony.
old fashioned oil lamp.
pair of black sunglasses.
pair of boxer shorts with red color.
pair of headphone with modern design.
pink cream doughnut.
pizza with cheese and pepperoni topping.
plastic water bottle.
purple cap mushroom.
red and black checkered picnic blanket.
red and pink apple.
red fire extinguisher with black handle.
rustic wooden barrel.
skateboard with green color.
small blue recycling bin.
small copper lantern.
small yellow curved banana.
spray paint can.
tall wooden bookshelf.
white and orange traffic cone.
white die with black pips.
white snowman with black top hat.
wooden desk.
wooden dresser with drawers and cabinets.
yellow and brown teddy bear.
Unconditional ShapNet Chair
Unconditional ShapNet Car
BibTeX
@article{wizadwongsa2024triflow,
author = {Wizadwongsa, Suttisak and Zhou, Jinfan and Li, Edward and Park, Jeong Joon},
title = {Taming Feed-forward Reconstruction Models as Latent Encoders for 3D Generative Models},
journal = {arxiv},
year = {2024},
}